RNN循环神经网络(二)
无论是随时间波动的股票价格,还是有着前后文逻辑的自然语言,RNN 都能捕捉其中的“时间依赖性”,今天将通过两个经典的入门实战项目:中国平安股价预测 和 字符级文本生成,来揭开 RNN 和 LSTM 的神秘面纱。从数据预处理、模型构建到结果分析,深入浅出地实战 RNN 及其变体 LSTM 的应用。
项目一:基于 SimpleRNN 的股价预测(回归问题)
股价预测是一个典型的 时间序列回归任务 。我们的目标是利用过去几天的历史价格,来预测下一天的收盘价。
1. 数据准备与预处理
在这个项目中,我们使用中国平安(zgpa_train.csv)的历史数据。为了让神经网络更好地收敛,我们首先进行归一化处理。
import pandas as pd
import numpy as np
data = pd.read_csv('zgpa_train.csv')
price = data.loc[:,'close']
price.head()
#归一化处理
price_norm = price/max(price)
print(price_norm)
%matplotlib inline
from matplotlib import pyplot as plt
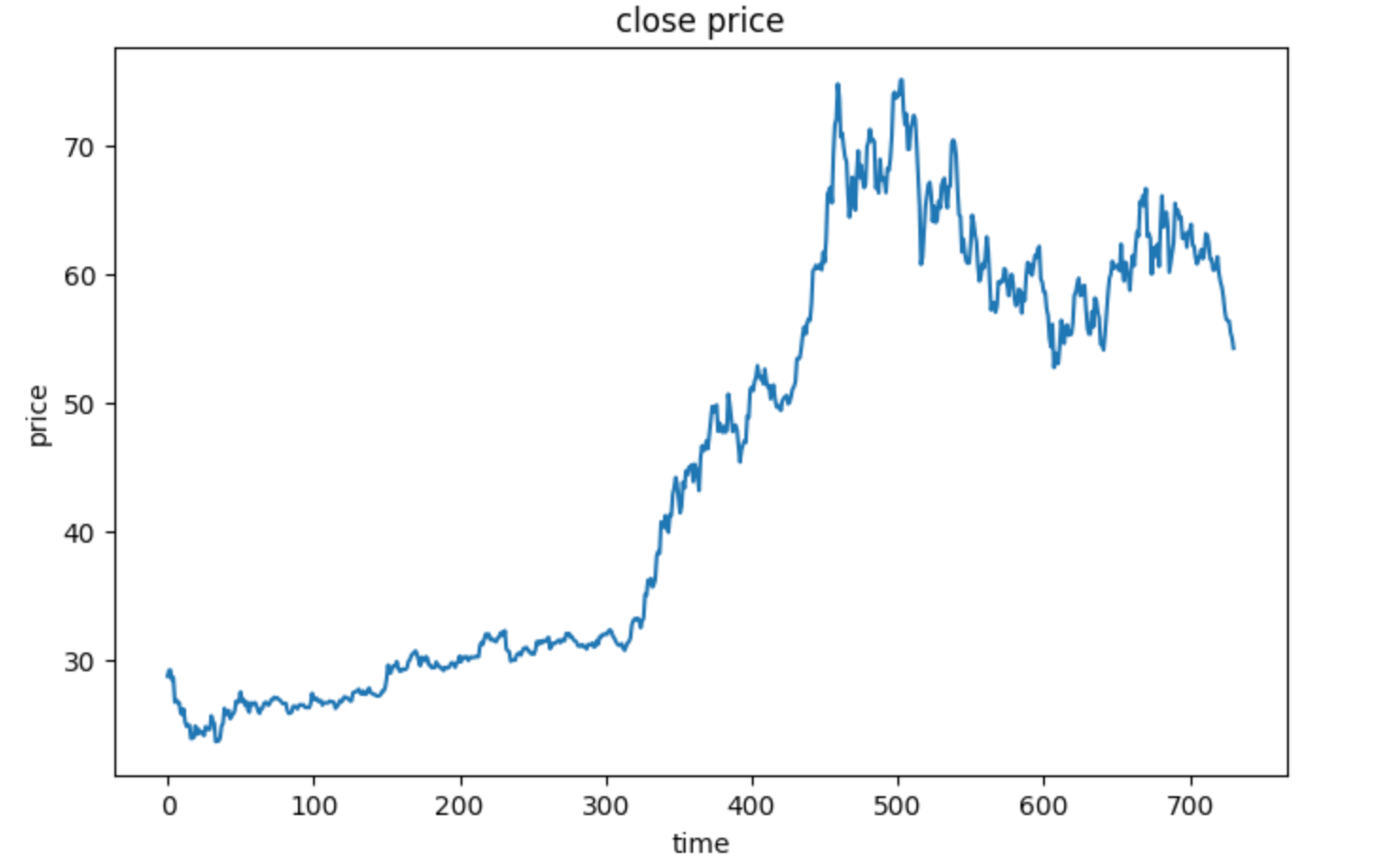
fig1 = plt.figure(figsize=(8,5))
plt.plot(price)
plt.title('close price')
plt.xlabel('time')
plt.ylabel('price')
plt.show()
核心难点:时间窗切分(Time Steps)
RNN 接收的数据是序列。我们需要定义一个 time_step(例如 8 天),即用过去 8 天的数据预测第 9 天。
def extract_data(data, time_step):
X, y = [], []
for i in range(len(data) - time_step):
X.append([a for a in data[i : i + time_step]])
y.append(data[i + time_step])
X = np.array(X)
# 调整形状为 (样本数, 时间步, 特征数)
X = X.reshape(X.shape[0], X.shape[1], 1)
return X, y
time_step = 8
X, y = extract_data(price_norm, time_step)
2.搭建 SimpleRNN 模型
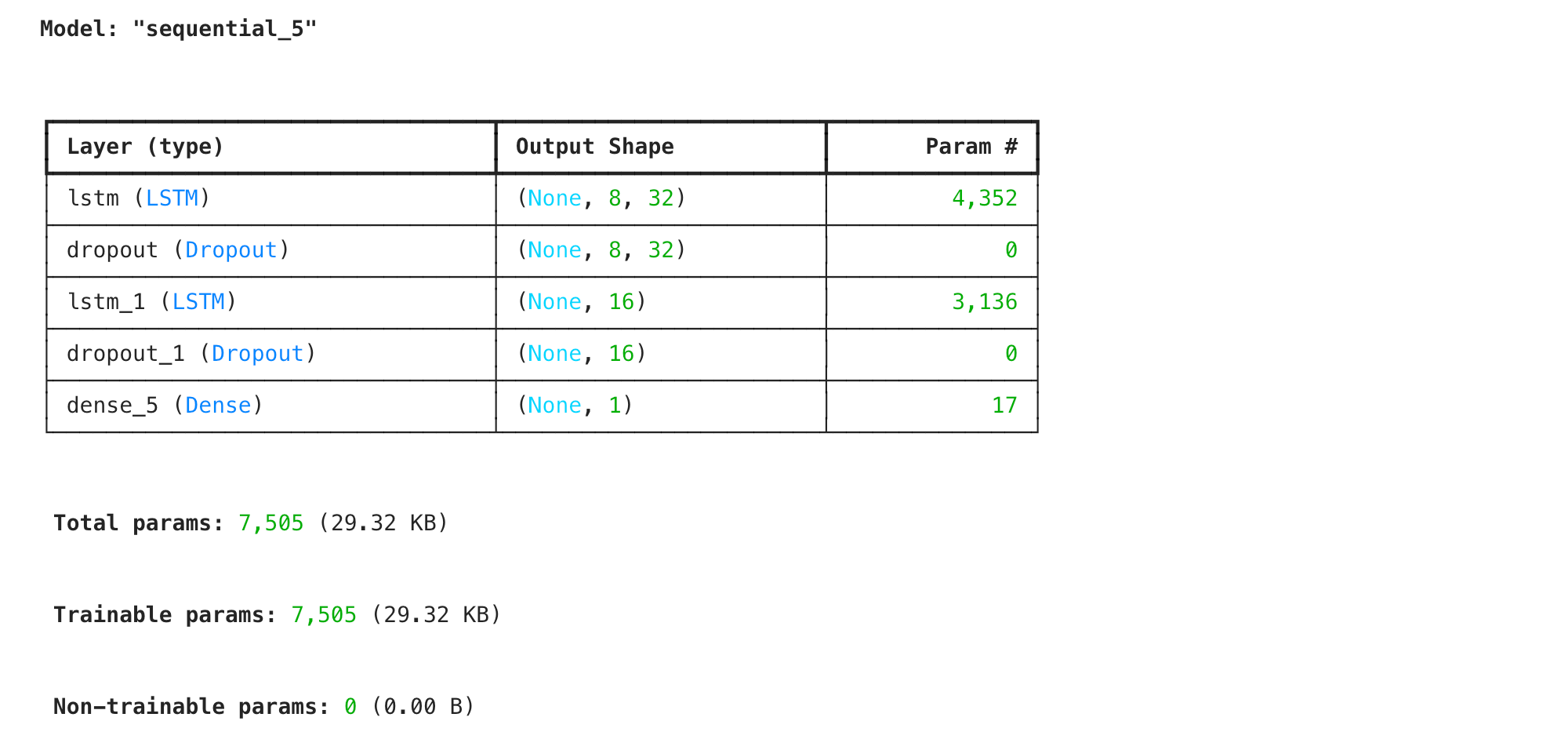
对于初学者,我们使用 Keras 搭建一个最简单的单层 RNN。
- 输入层:接收 (8, 1) 的序列数据。
- 隐藏层:SimpleRNN,5 个神经元,激活函数为 ReLU。
- 输出层:Dense,1 个神经元(预测具体的股价数值),激活函数为 Linear。
#set up the model
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN, Input
model = Sequential([
Input(shape=(time_step, 1)), # 新版 Keras 推荐写法
SimpleRNN(units=5, activation='relu'),
Dense(units=1, activation='linear')
])
#configure the model
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
3. 训练与预测
#train the model
model.fit(X,y,batch_size=30,epochs=200)
#make prediction based on the training data
y_train_predict = model.predict(X)*max(price)
y_train = [i*max(price) for i in y]
print(y_train_predict,y_train)
fig2 = plt.figure(figsize=(8,5))
plt.plot(y_train,label='real price')
plt.plot(y_train_predict,label='predict price')
plt.title('close price')
plt.xlabel('time')
plt.ylabel('price')
plt.legend()
plt.show()
经过 200 个 Epoch 的训练,模型 Loss 降到了非常低的水平。我们将预测出的归一化数据还原为真实股价,并与真实值对比。
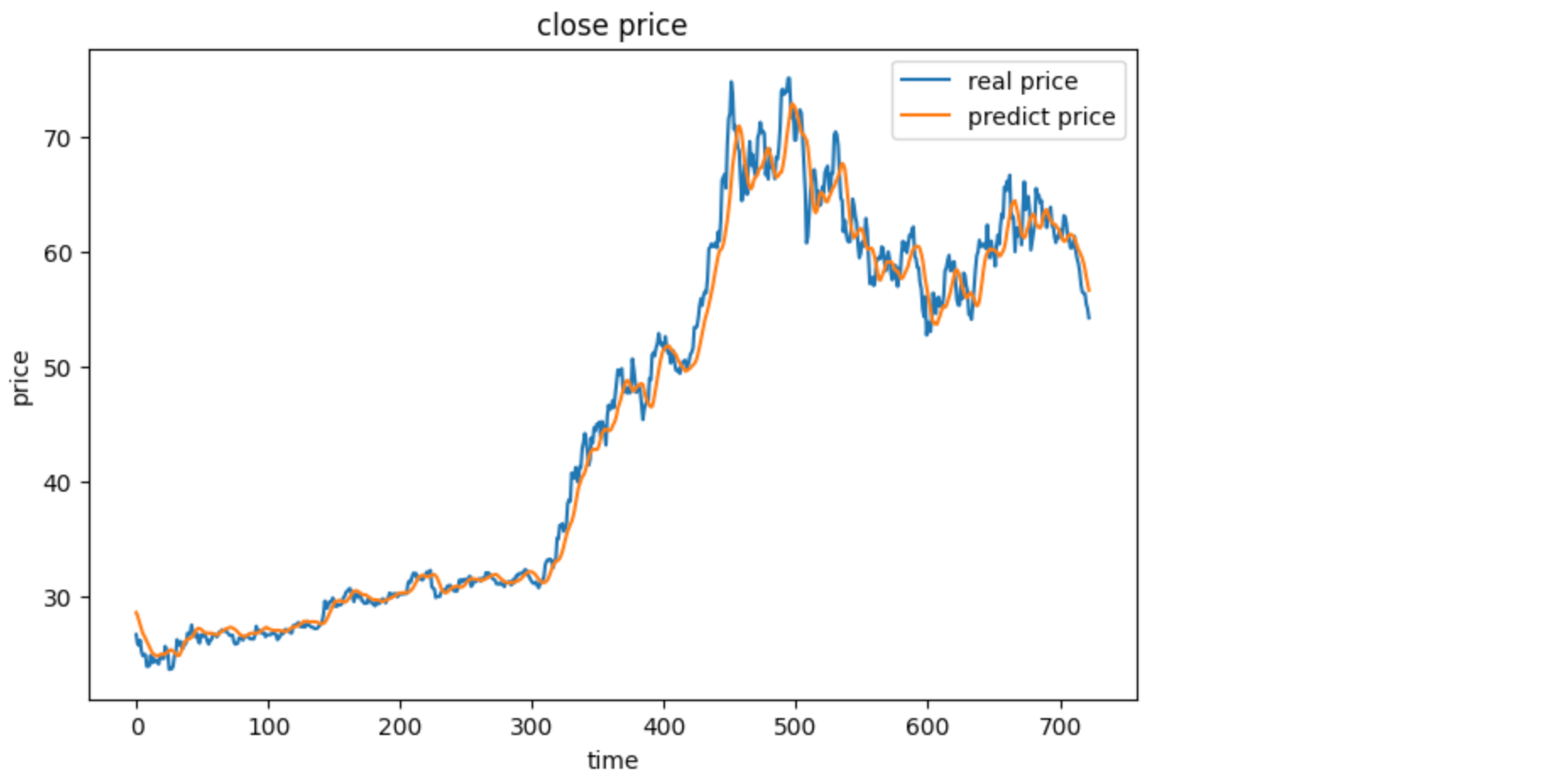 结果分析:
从可视化结果来看,RNN 能够很好地拟合股价的大致趋势。
结果分析:
从可视化结果来看,RNN 能够很好地拟合股价的大致趋势。
项目二:基于 LSTM 的文本生成(分类问题)
第二个项目更有趣:让 AI 学会写字。给定一段关于 “Flare” 老师介绍的文本,让模型学会预测下一个字符是什么。这是一个多分类任务。
1. 文本向量化(Dictionary Mapping)
计算机不认识 “a, b, c”,只认识数字。我们需要建立字符与数字的映射字典。
data = "flare is a teacher in ai industry..."
letters = list(set(data))
num_letters = len(letters)
# 建立字符索引字典
char_to_int = {c: i for i, c in enumerate(letters)}
int_to_char = {i: c for i, c in enumerate(letters)}
2. 数据预处理
与股价预测类似,我们也需要滑动窗口。
- 输入 (X):长度为 20 的字符序列(转换为数字索引)。
- 输出 (y):第 21 个字符。
- One-Hot 编码:为了进行分类预测,我们需要将输入和输出进行独热编码处理。
from keras.utils import to_categorical
# ... 数据提取逻辑同上,加上 to_categorical 处理 ...
# 最终 X 的形状: (样本数, 20, 23) -> 23 是字符总数(字典大小)
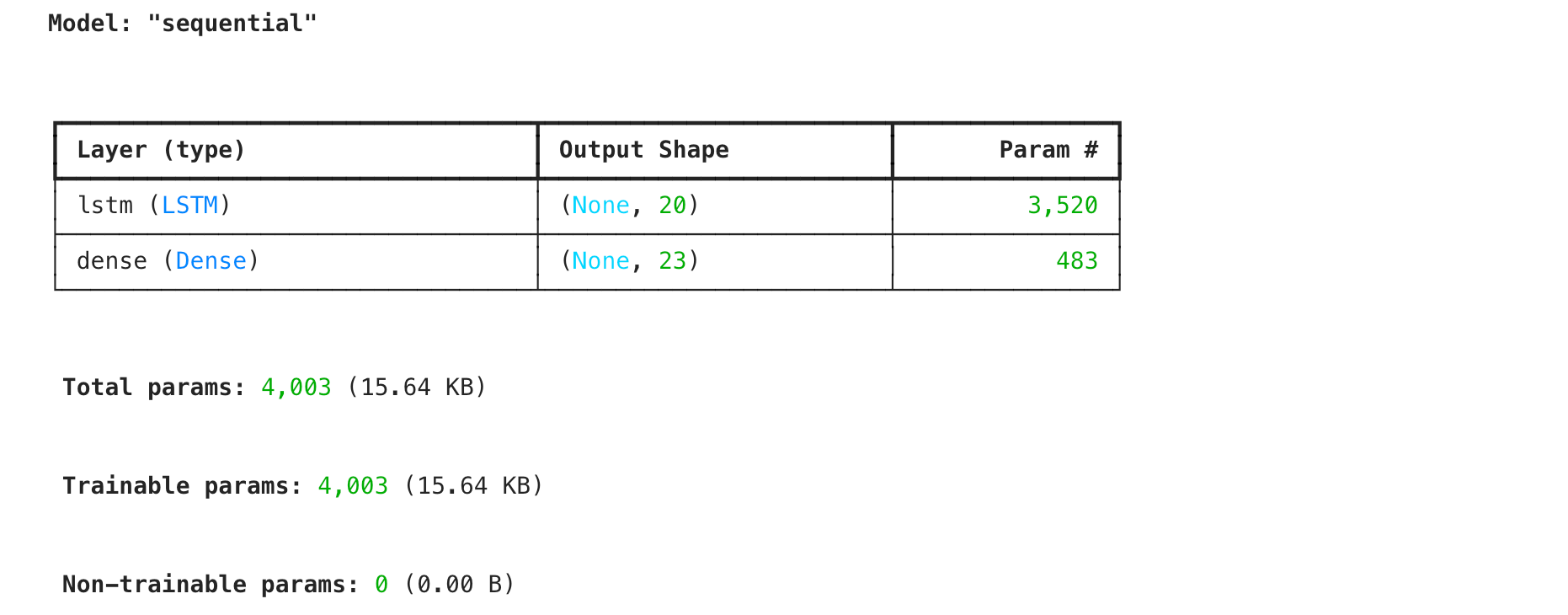
3. 搭建 LSTM 模型
处理长序列文本时,SimpleRNN 容易出现梯度消失问题,记不住太前面的信息。因此我们这里使用 LSTM (Long Short-Term Memory)。
- LSTM 层:20 个单元,能够记忆更长期的上下文信息。
- 输出层:Dense 层,神经元数量等于字典大小(23),使用
softmax输出每个字符的概率。
from keras.layers import LSTM
model = Sequential()
model.add(LSTM(units=20, input_shape=(20, num_letters), activation='relu'))
model.add(Dense(units=num_letters, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
4. 实战测试
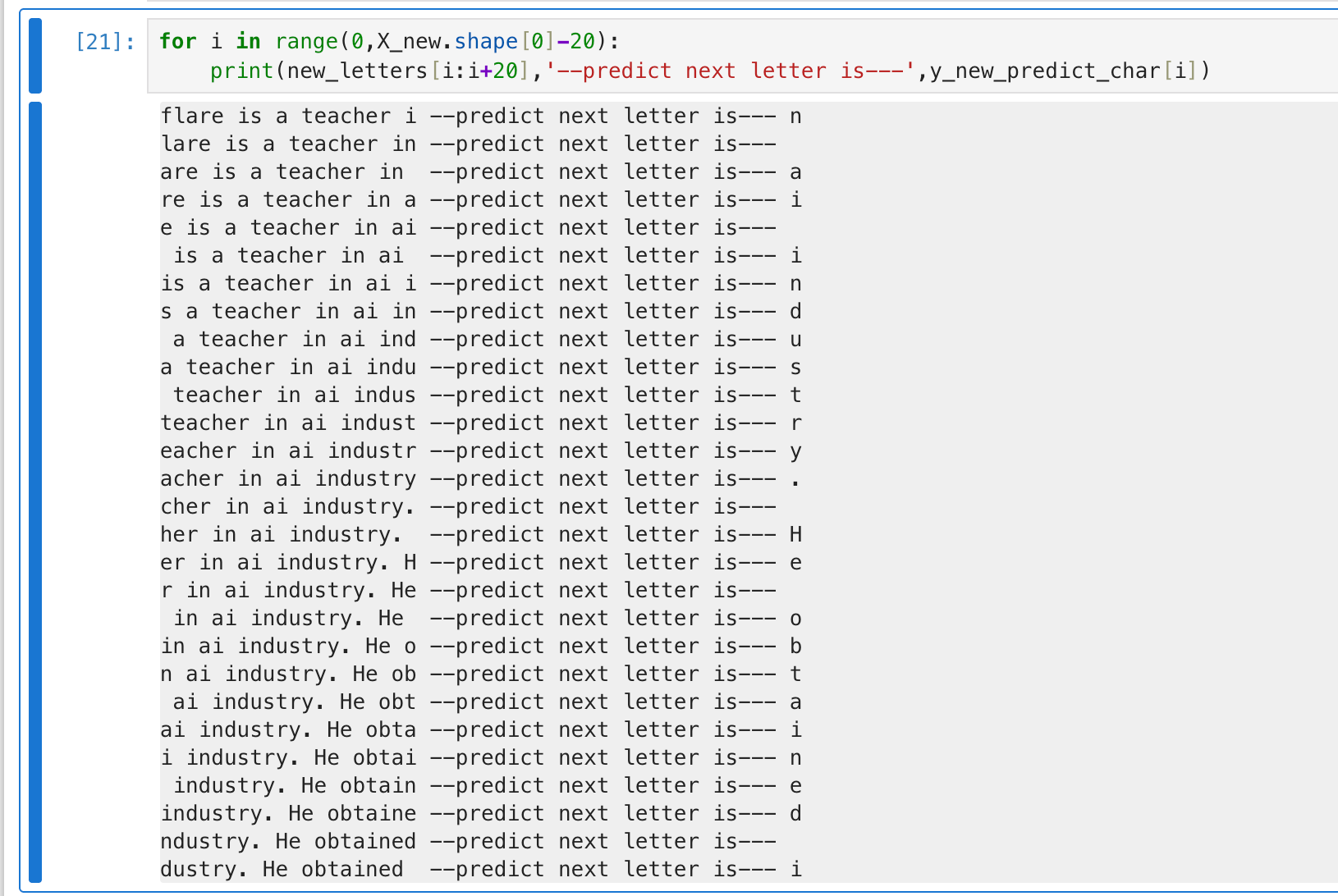
模型训练后达到了约 95% 的准确率。我们输入一段从未见过的测试文本:
" flare is a teacher in ai industry. He obtained his phd in Australia."
模型逐字预测后续字符:
flare is a teacher i -> n
lare is a teacher in -> (space)
are is a teacher in -> a
...
最终模型成功补全了单词,甚至理解了句号后面需要空格。
总结与对比
通过这两个案例,我们清晰地看到了 RNN 家族在不同场景下的应用模式:
| 特性 | 股价预测 (Project 1) | 文本生成 (Project 2) |
|---|---|---|
| 任务类型 | 回归 (Regression) | 分类 (Classification) |
| 核心模型 | SimpleRNN (基础循环网络) | LSTM (长短期记忆网络) |
| 输入数据 | 连续数值 (归一化) | 离散字符 (One-Hot编码) |
| 输出层激活 | linear (输出任意实数) | softmax (输出概率分布) |
| 损失函数 | mean_squared_error (均方误差) | categorical_crossentropy (交叉熵) |
实战建议:
- 数据预处理是关键:无论是股价的归一化,还是文本的字典映射,格式正确的输入是模型跑通的前提。
- LSTM 优于 RNN:在绝大多数序列任务(特别是 NLP)中,优先选择 LSTM 或 GRU,因为它们能更好地处理长距离依赖。
- 维度陷阱:时刻注意 Tensor 的形状
(Batch_Size, Time_Steps, Features),这是新手最容易报错的地方。