迁移学习与混合模型
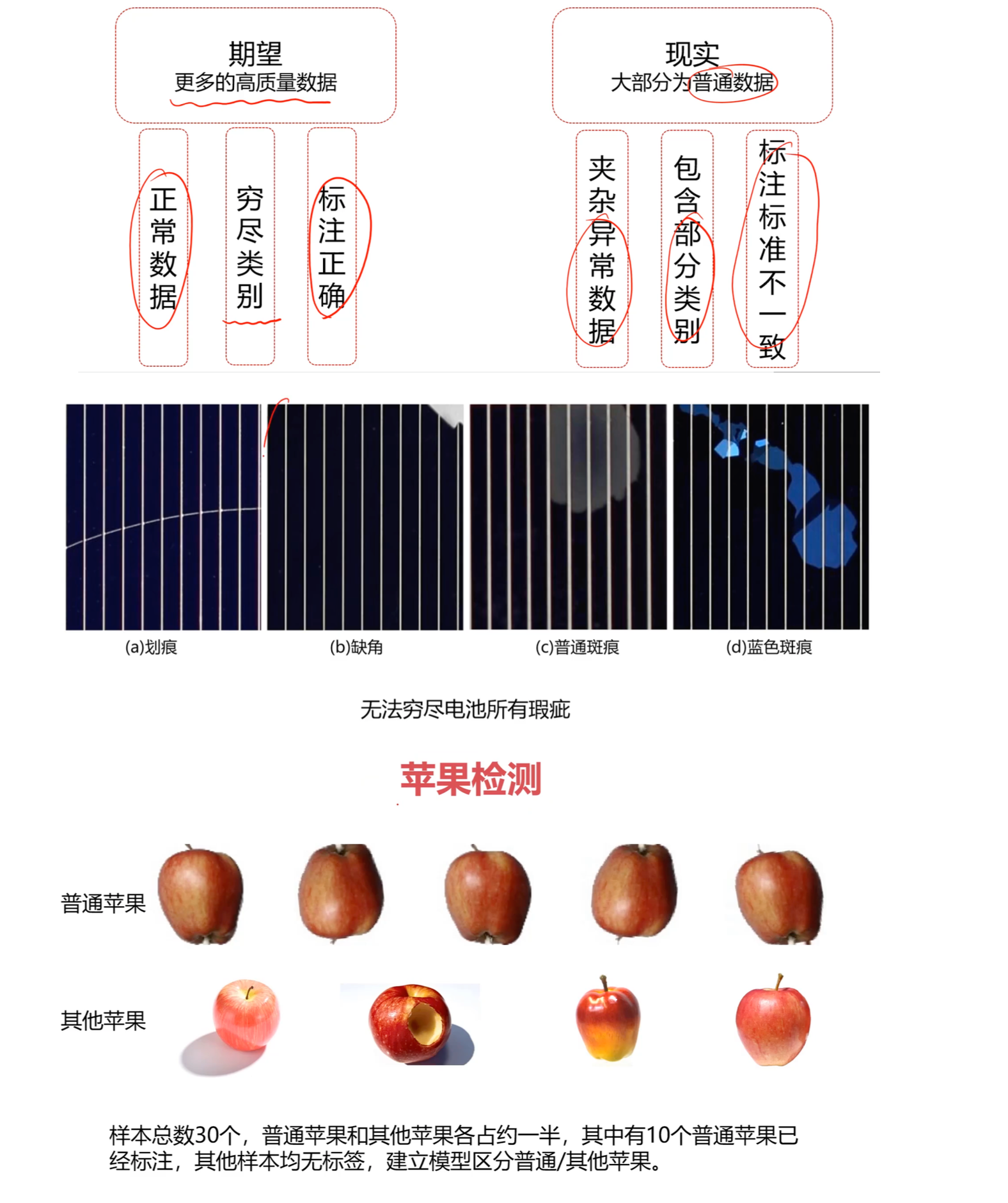
在机器学习的现实应用中,我们往往面临“理想很丰满,现实很骨感”的局面:期望拥有海量的高质量数据,实际上却充满了标注不一致、含噪声的普通数据,甚至大量无标签数据。如何利用有限的数据训练出高效的模型?本文重点探讨迁移学习(Transfer Learning)、在线学习(Online Learning)、半监督学习(Semi-Supervised Learning)以及混合模型(Hybrid Models)的组合策略。
一、迁移学习:站在巨人的肩膀上
1. 核心概念
迁移学习(Transfer Learning)的核心思想是将某个领域或任务上学习到的知识(模型A),应用到不同但相关的领域或任务中(建立模型B)。
- 形象比喻: 就像老师教学生传授核心知识点,或者学会了骑自行车有助于学骑摩托车,学会了自由泳有助于学蛙泳。
- 本质: 模型A存储了结构和权重系数,模型B基于新数据,对模型A的部分结构或权重进行更新。
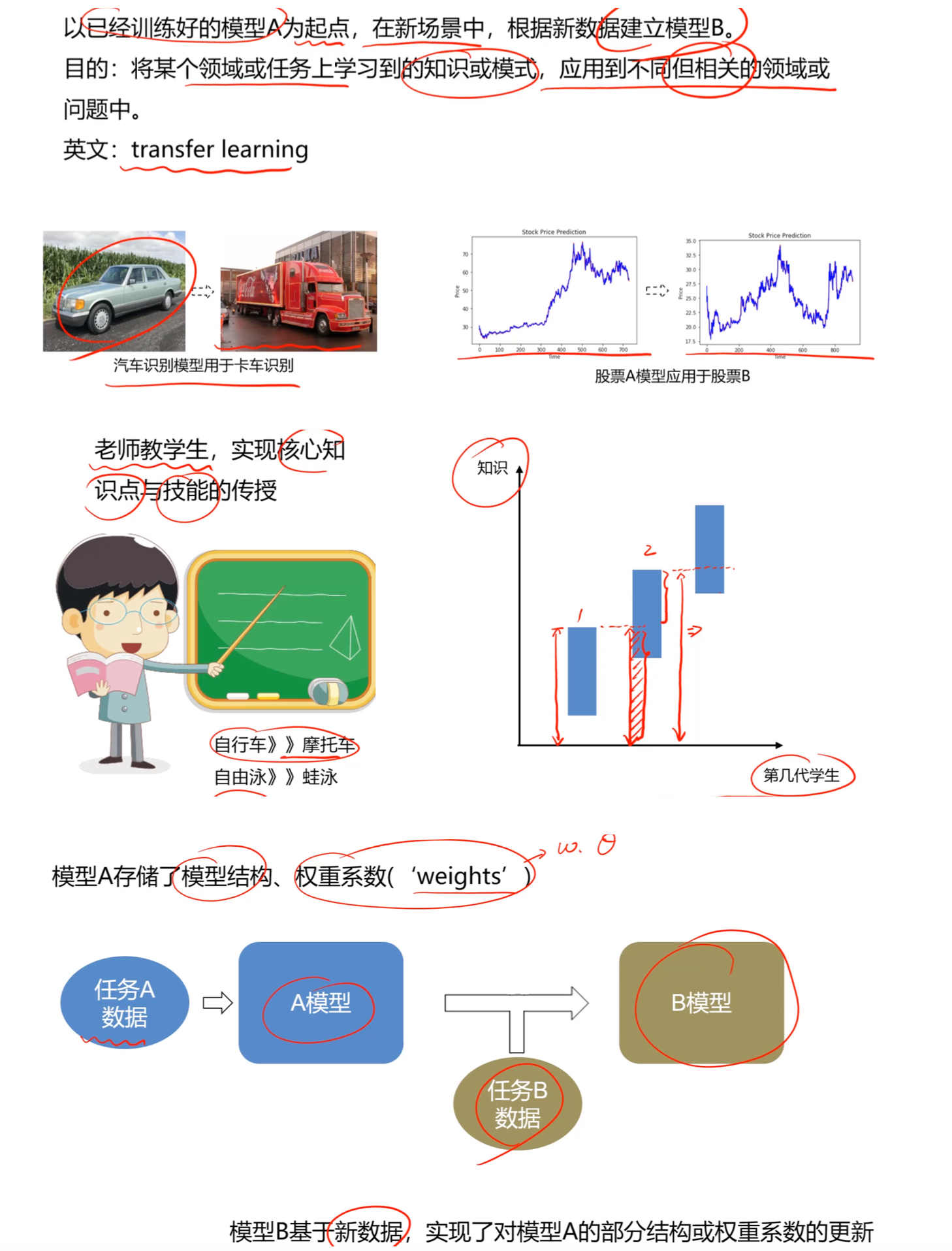
2. 为什么使用迁移学习?
相比于从头训练全新的模型,迁移学习具有巨大的优势,形成了一个"时间-数据-表现"的铁三角优势:
- 数据: 对样本数据量的需求相对较小。
- 时间: 待更新参数少,训练速度快。
- 表现: 通常比很多全新的模型有更好的表现。
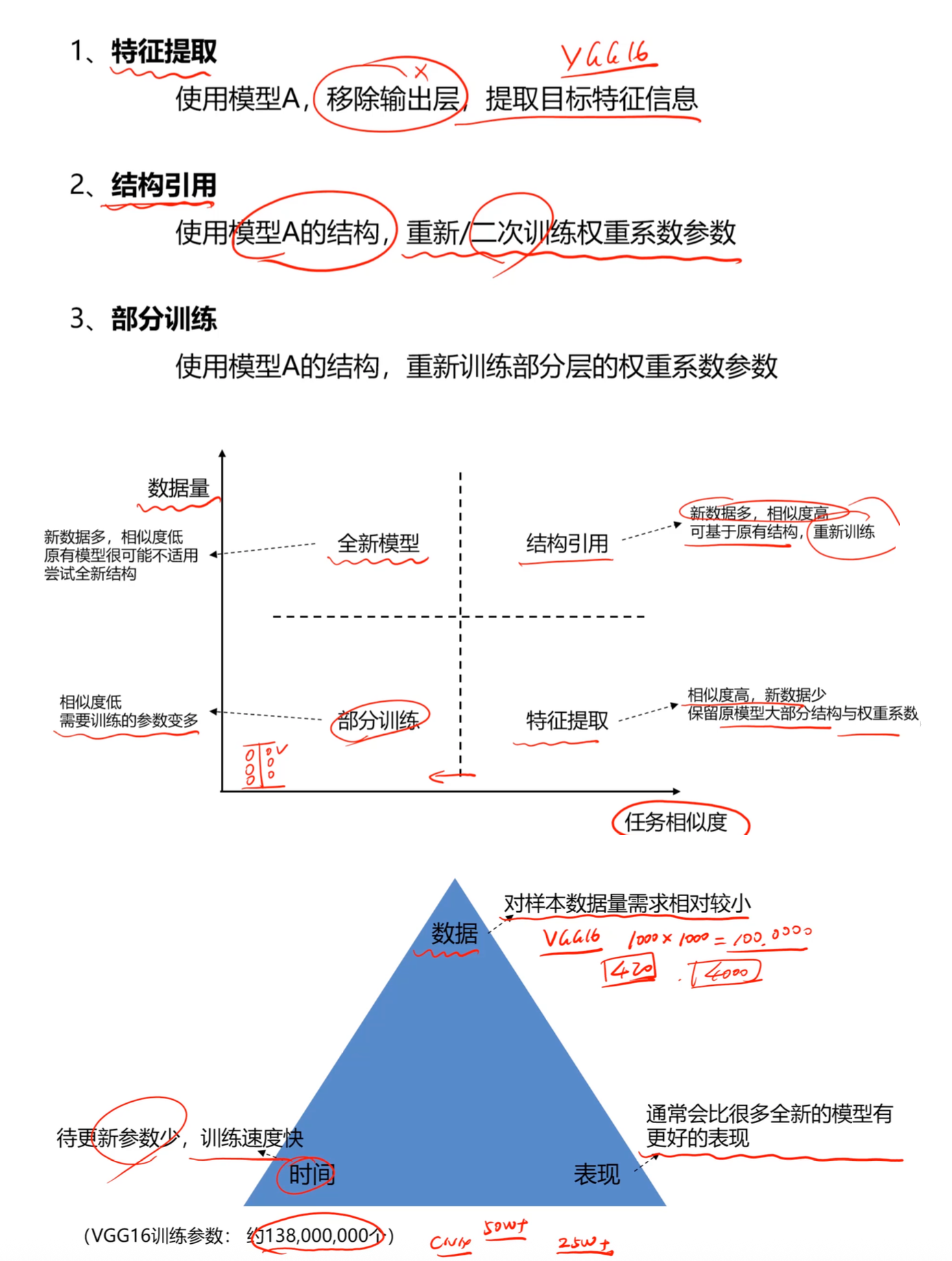
- 案例: VGG16模型拥有约1.38亿个训练参数,若直接训练需要海量数据(如100万张图),而通过迁移学习可以大幅降低门槛。
3. 策略选择矩阵:怎么"迁移"?
根据新数据的数量和任务的相似度,我们可以选择不同的迁移策略:
- 场景一:相似度高,新数据少
- 策略:特征提取 (Feature Extraction)
- 做法: 保留原模型大部分结构与权重系数,只移除输出层提取特征,重新训练少量参数。
- 场景二:相似度高,新数据多
- 策略:结构引用/微调 (Structure Reuse)
- 做法: 基于原有结构,使用新数据重新训练权重系数参数。
- 场景三:相似度低,新数据多
- 策略:全新模型或部分训练
- 做法: 原有模型可能不适用,尝试全新结构或只保留部分层进行训练。
- 场景四:相似度低,新数据少
- 难点: 需要训练的参数变多,但数据不足,这是最棘手的情况。
二、在线学习与半监督学习:应对动态与无标签数据
1. 在线学习 (Online Learning)
当应用场景中存在连续的数据流时(如航空公司根据实时购票情况调整价格),传统的离线训练不再适用。
定义: 给已训练好的模型输入新数据,模型在不需要重新训练全量数据的基础上实现更新。
特点: 不改变模型结构,根据新数据 $(x, y)$ 实时更新权重系数 $\theta$。
更新公式: $$temp_{\theta_{j}}=\theta_{j}-\alpha\times(y_{predict}-\hat{\vartheta})\times(x_{j})$$
$$\theta_{j}=temp_{\theta_{j}}$$
2. 半监督学习 (Semi-Supervised Learning)
面对大量无标签数据和少量有标签数据(如电池瑕疵检测、苹果分类),由于无法穷尽所有瑕疵类别,半监督学习非常关键。
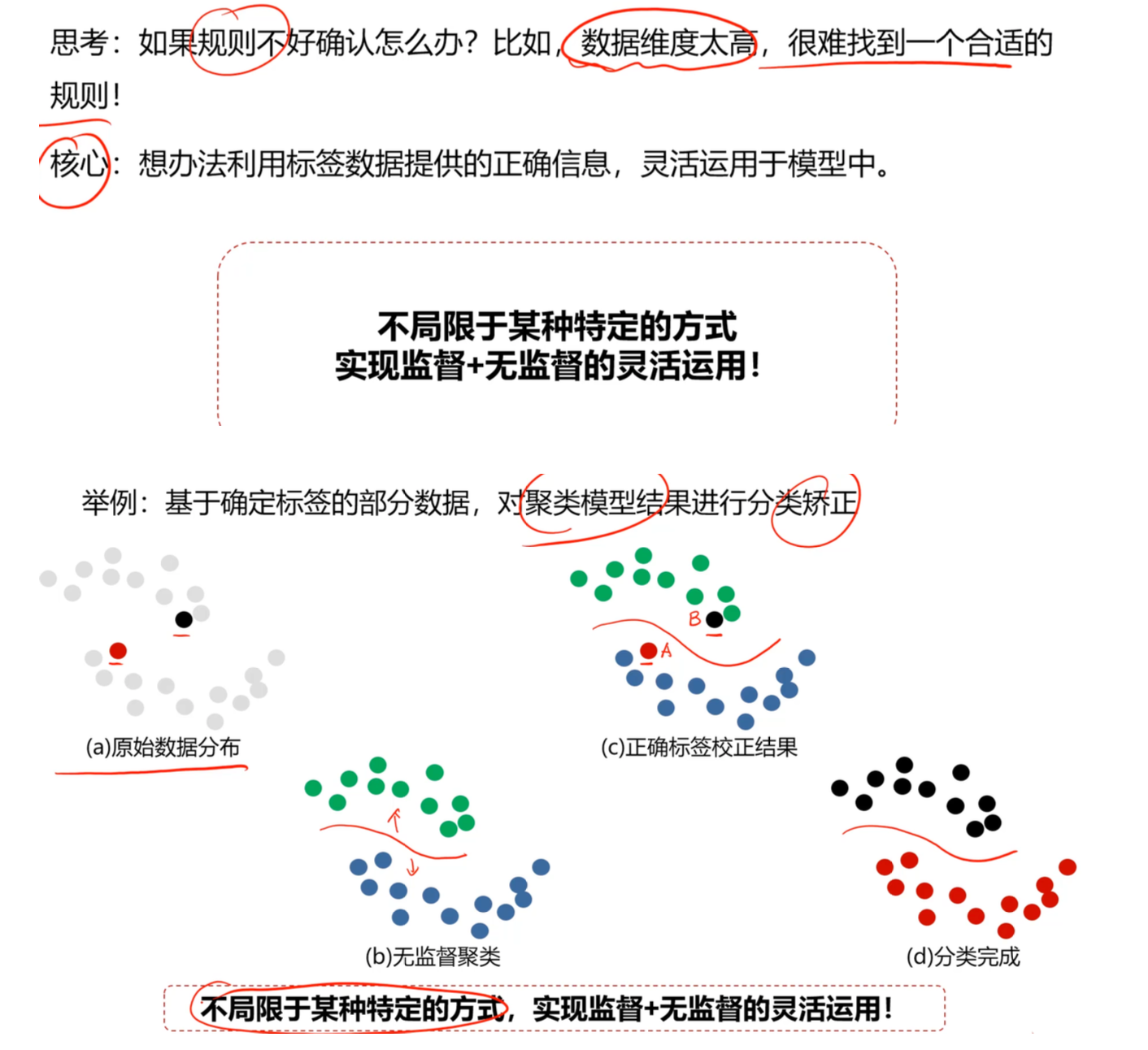
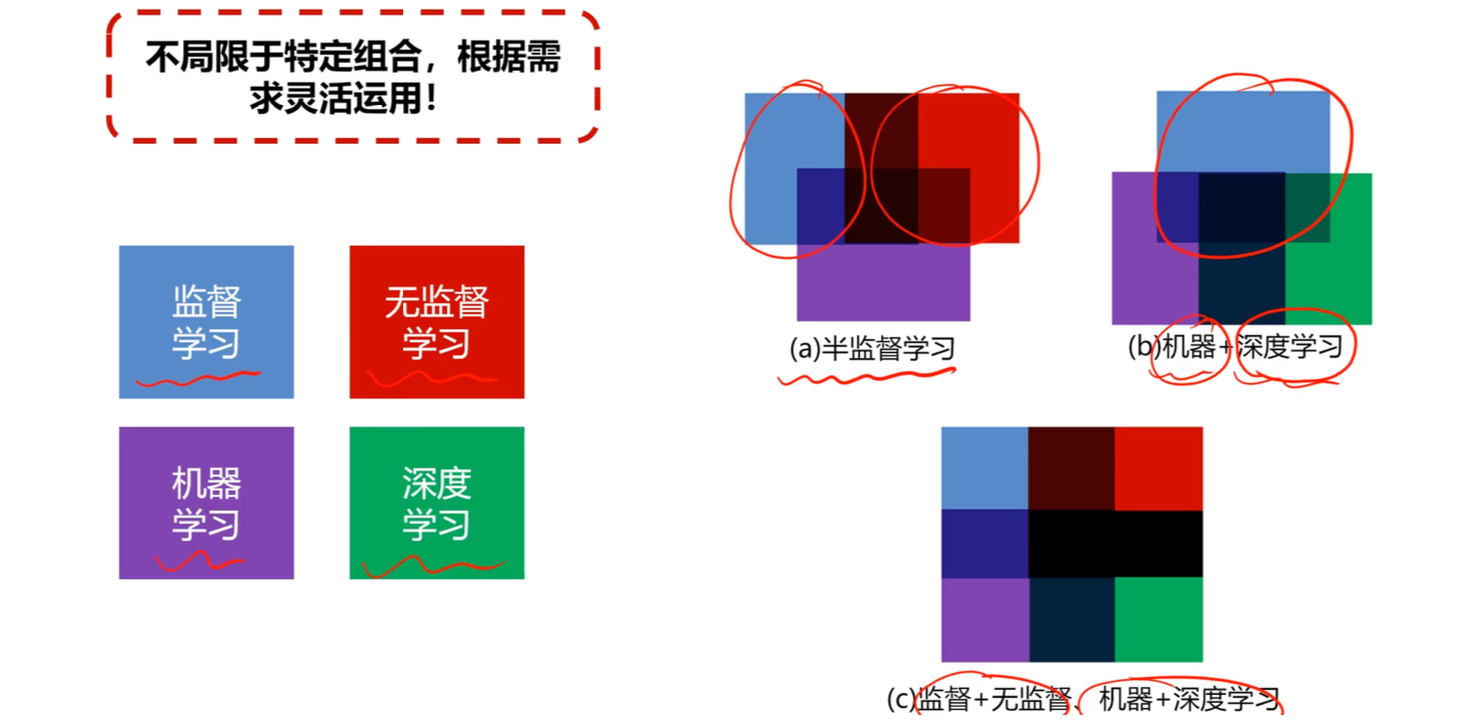
- 核心逻辑: 监督学习 + 无监督学习,利用有标记样本挖掘无标记样本中的价值信息。
- 关键技术:伪标签学习 (Pseudo Labeling)
- 用初始标签数据训练一个分类器。
- 用该分类器对无标签数据进行预测,产生"伪标签"。
- 挑选出置信度高(认为分类正确)的数据,加入训练集进行二次训练。
- 灵活运用: 也可以利用有标签数据对聚类模型(无监督)的结果进行分类矫正。
三、混合模型:打破边界的组合拳
在解决复杂问题时,不要局限于单一算法。真正的核心是根据需求灵活运用各种工具。
1. 机器学习 + 深度学习 (ML + DL)
深度学习(Deep Learning)是机器学习(Machine Learning)的一个子集,但两者可以互补。
- 数据预处理阶段(ML): 使用机器学习算法进行数据降维、异常检测。
- 特征/分类阶段(DL/ML):
- 利用 MLP(多层感知器)、CNN(卷积神经网络)、RNN(循环神经网络)处理复杂特征。
- 利用传统的聚类(Kmeans)、分类(逻辑回归、决策树)或回归算法处理特定逻辑。
2. 混合实战思路
- 场景: 遇到复杂的聚类问题,传统算法效果不好,且MLP无法直接实现聚类。
- 解决方案:
- 有标签数据提取特征: 用有标签数据训练网络(如VGG16)。
- 隐藏层应用: 通过隐藏层提取特征。
- 建模预测: 基于提取的特征数据,对无标签数据进行后续的建模(如聚类或预测)。
总结
无论是迁移学习、在线学习还是混合模型,其本质都是为了解决数据量、标注成本和模型泛化能力之间的矛盾。正如课件最后所强调的:“不局限于特定组合,根据需求灵活运用!”