机器学习环境配置
以前在学习线性回归算法的时候主要使用 Octave 作为主要编程语言,现在想来无论是画图还是矩阵运算不如Python的numpy、matplotlib等方便快捷,现主要记录下通过Anaconda与Jupyter NoteBook搭建机器学习环境的过程。
以前在学习线性回归算法的时候主要使用 Octave 作为主要编程语言,现在想来无论是画图还是矩阵运算不如Python的numpy、matplotlib等方便快捷,现主要记录下通过Anaconda与Jupyter NoteBook搭建机器学习环境的过程。
有时候忽然回想起小时候的故事感觉很有趣,也是一种不错的回忆,特此记录一下。每次想起了就会想起在老家,奶奶讲故事那会儿,都是老家那边盛传的故事,可能每个人听到的版本不同,但是大致框架是相同的,有的故事没有主旨,就是单纯吓人、或者神话故事,而有的故事就和寓言一样,有某种教育意义。反正我如果某刻想起了就在此随时补充。
有句话说得好:折腾永无止境啊!前段时间为了随时能够看看旧照片、豆瓣TOP250的电影,入手了绿联云的DX4600的NAS(我是一个NAS菜鸟玩家,唯一的要求就是外网访问不卡、支持视频硬解,稳定!),准确的说它不配称作NAS,因为NAS系统都是有自己完备的软件生态的,比如DSM,即使安装黑群晖也有勉强不错的体验。那么绿联的这款为什么最终让我如此唾弃呢?

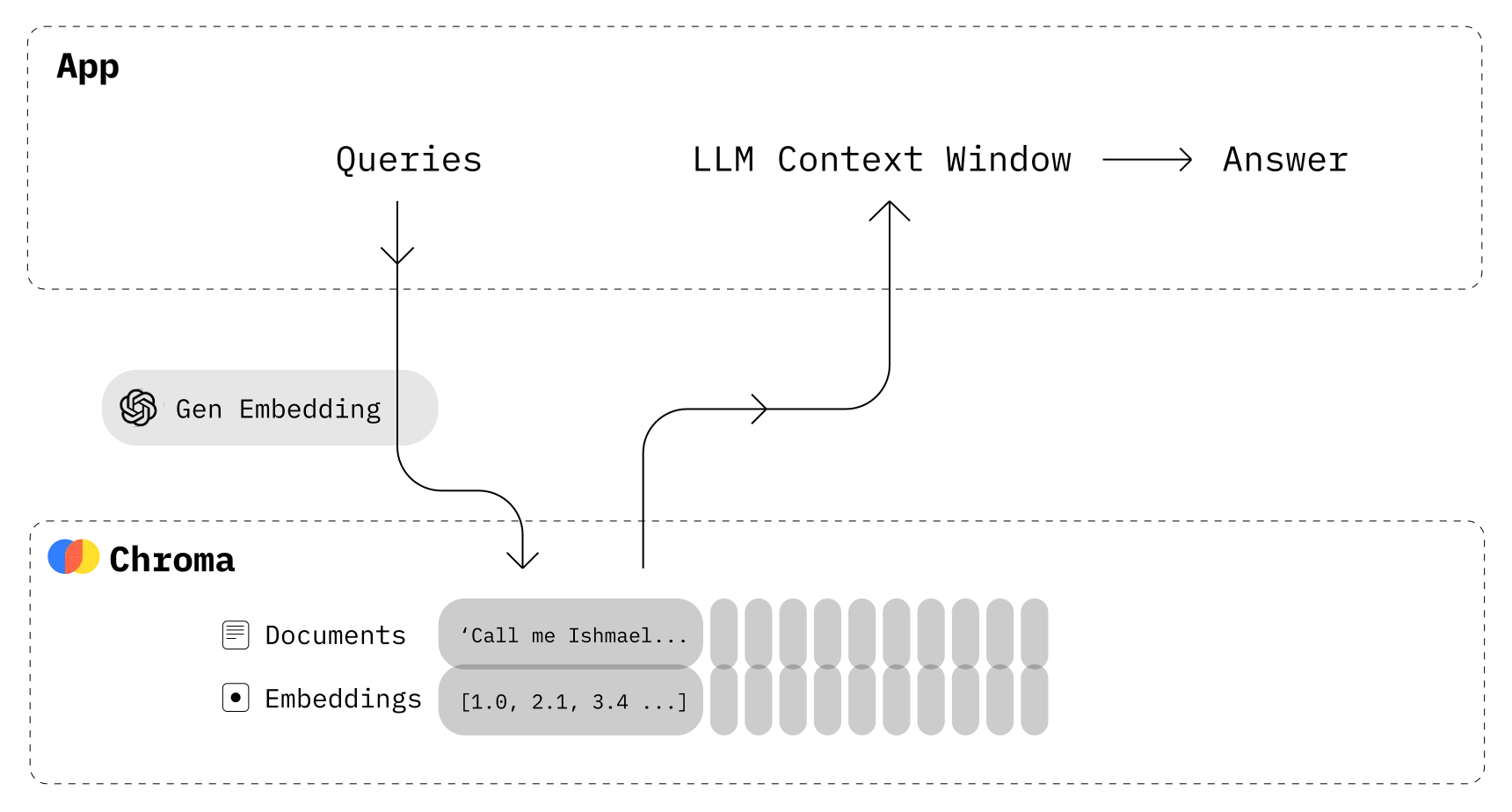
在大模型的应用中,不断涌现出B端对专用数据的需求、C端对个性化与自动化的需求,带来给大模型增加记忆功能的刚性需求,相关产品需求量快速增长。众所周知,如今如火如荼的ChatGPT确实可以帮助我们解决许多问题,但是其作为一款语言大模型,从原理上就不容易实现记录与用户的全部历史对话,以及历史对话过程中的关键信息,这些信息往往只存在一次Session中。为了解决大模型没有“记忆”的问题,引入了向量数据库。
在上一篇文章中,我们学习了光线追踪的基本原理:向场景发射光线,并计算它与物体是否相交。听起来很简单,对吧?
但这里隐藏着一个巨大的性能陷阱:假设你的场景中有 1000 万个三角形,需要渲染 1920×1080 分辨率的图像。
本文基于 GAMES101 Lecture 14 的内容,介绍三种主流的光线追踪加速结构,帮助你理解现代渲染器如何将渲染时间从几天缩短到几秒。
核心思想:如果光线连物体所在的区域都没碰到,那就不需要测试区域内的物体。

光线追踪(Ray Tracing)是计算机图形学中最经典、最优雅的渲染技术之一。它通过模拟光线在场景中的传播过程,能够生成具有真实感的图像——包括精确的阴影、镜面反射、透明折射等效果。从皮克斯的动画电影到如今支持 RTX 的游戏,光线追踪技术无处不在。
本文基于 GAMES101(闫令琪)Lecture 13-14 的内容,从理论到实践,系统介绍光线追踪的核心原理。我们将不依赖任何图形库,仅使用 Python 的基础数学运算,从零实现一个完整的光线追踪渲染器。通过这个case,可以深入理解:
最终,我们将从零开始手写光线追踪算法的实现,不过我的是Python版本,嘿嘿~ 反正原理都一样的
当邮件中有1000封邮件,商店列表中有1000个物体,如果直接实例化1000条数据显示则会大大增加 DrawCall,而大量不可见的数据被 Mask 组件排除在可视范围之外,但他们依然存在,这时就需要考虑通过一个无限滑动的 ScrollView 来优化渲染性能,下面这种复用方式提供了一个通用的思路来处理此类问题。
热修复的原理主要有两种技术,一是不需要启动APP就能实现修复,在 Native 层实现的。一种是需要启动 App,在JAVA层实现的。 本文会介绍 Android 热修复的最基本原理( Java 层实现的,需要重启 App),那就是通过 ClassLoader 的机制,通过反射先加载补丁包的类,从而替换掉存在 BUG 的类,达到修复的目的。